You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
Project Orbiter Galaxy
- Thread starter jedidia
- Start date
Man, I suck at this, but it works at last... :thumbup:
you were right, checking from both sides wasn't a great Idea. I thought it would need less iterations, but the opposite turned out to be true. Short Range pathfinding (within the currently generated cubes) workes like a charm now. Let's see what I can do about the long distance jumps... h:
h:
Linguofreak, have you already started to expand your tables to the higher mass classes? If not, I'll just make up some stuff for testing. By the way, getting from one mass class to another can be quite a pain with the current data. Procyon is out of limits of the short range solution, no compatible jumps within 270 cubic parsec. Once I finish the pathfinding routines I'll send you a version of the standalone so you can play around with it and fiddle the ranges to your liking. Might still be a while, though.
---------- Post added at 09:53 PM ---------- Previous post was at 05:28 PM ----------
Ok, now there is a way to reach procyon... I had a conversion to integer left from my experimental code, so the mass classes weren't evaluated as they should. Now, after having fixed that, maybe I can turn my attention to the long distance trouble...
you were right, checking from both sides wasn't a great Idea. I thought it would need less iterations, but the opposite turned out to be true. Short Range pathfinding (within the currently generated cubes) workes like a charm now. Let's see what I can do about the long distance jumps...
h:Linguofreak, have you already started to expand your tables to the higher mass classes? If not, I'll just make up some stuff for testing. By the way, getting from one mass class to another can be quite a pain with the current data. Procyon is out of limits of the short range solution, no compatible jumps within 270 cubic parsec. Once I finish the pathfinding routines I'll send you a version of the standalone so you can play around with it and fiddle the ranges to your liking. Might still be a while, though.
---------- Post added at 09:53 PM ---------- Previous post was at 05:28 PM ----------
Ok, now there is a way to reach procyon... I had a conversion to integer left from my experimental code, so the mass classes weren't evaluated as they should. Now, after having fixed that, maybe I can turn my attention to the long distance trouble...
Linguofreak
Well-known member
Linguofreak, have you already started to expand your tables to the higher mass classes? If not, I'll just make up some stuff for testing.
No I haven't. One thing I'm thinking is that mass class 0 (the highest-mass) one, goes up a bit too high on the scale if we're going to be extending things. It might be better to put its upper limit somewhere around 2.5 or 3 solar masses.
(One thing for extending the table: The distance for the bottom cell in each column was basically just thought up off the top of my head. But within each column, each number = (1/1.15) * (the number below it).)
(One thing for extending the table: The distance for the bottom cell in each column was basically just thought up off the top of my head. But within each column, each number = (1/1.15) * (the number below it).)
ah, that's the relation. I knew there had to be one... For me it would be nice if I could leave fiddling the tables up to you (they're your tables, after all) and move on to other things once the long distance pathfinding works satisfacotrily. Once you get a preliminary version, that should give you a pretty good opportunity to test and refine the data.
Linguofreak
Well-known member
ah, that's the relation. I knew there had to be one... For me it would be nice if I could leave fiddling the tables up to you (they're your tables, after all) and move on to other things once the long distance pathfinding works satisfacotrily. Once you get a preliminary version, that should give you a pretty good opportunity to test and refine the data.
OK, let me pull some numbers off the top of my head:
We'll change mass classes 5, 4, 3, 2, 1, and 0 to being A, B, C, D, E, and F, respectively (that gives us room to add more at the top of the mass range without going into negative numbers). We'll change the upper limit for class F to 2.87. A new class, G, will run from 2.85 to 4.32 solar masses, and the distance for a G to G link will be 36.52 light years (apply the 1/1.15 rule to derive links between G and lower mass classes). Class H will run from 4.30 to 6.26 solar masses, and an H to H link will have a distance of 46.74 ly.
Class I: 6.24-8.77, dist 62.63
Class J: 8.75-10.15, dist 90.19
Can you tell me how those hold up? The problem is that I only have one star in my data set in the range that we're now making class G, and nothing higher, and my data set only covers a ~50 light year radius around Sol, so I can't really test my numbers out.
Well, I didn't expect them immediately, but thanks none the less :lol:
I made up some numbers just for the sake of writing the long-distance alorithm, they are easy to replace afterwards (neither the distances nor the mass classes themselfes nor the number of mass classes are hard coded, you can do pretty much everything in the config file). So I'll just use that to come up with an algorithm, send you an exe file and the data table, and you'll be able to test to your heart's content.
I think that designating letters to the mass classes might lead to some confusion with spectral classes, though. Although in the generator there isn't really a designation at all, only ranges and indexes, so it probably doesn't matter what we call them here.
I made up some numbers just for the sake of writing the long-distance alorithm, they are easy to replace afterwards (neither the distances nor the mass classes themselfes nor the number of mass classes are hard coded, you can do pretty much everything in the config file). So I'll just use that to come up with an algorithm, send you an exe file and the data table, and you'll be able to test to your heart's content.
I think that designating letters to the mass classes might lead to some confusion with spectral classes, though. Although in the generator there isn't really a designation at all, only ranges and indexes, so it probably doesn't matter what we call them here.
Linguofreak
Well-known member
Well, I didn't expect them immediately, but thanks none the less :lol:
There wasn't much reason not to come up with them immediately. Most of the work was in thinking up how I'd have to structure things to get the effect I wanted. Once I had that, it was simply a matter of throwing in (somewhat) random numbers. By luck, for the first six mass classes, the numbers worked really well. When you asked for more mass classes, I just made up more random numbers.
That's one reason it might be better for you to make up the random numbers: You're the one with the data set with the high mass stars and the program that works with that data set, so you're the one that can check how things work quickly.
I made up some numbers just for the sake of writing the long-distance alorithm, they are easy to replace afterwards (neither the distances nor the mass classes themselfes nor the number of mass classes are hard coded, you can do pretty much everything in the config file). So I'll just use that to come up with an algorithm, send you an exe file and the data table, and you'll be able to test to your heart's content.
I think that designating letters to the mass classes might lead to some confusion with spectral classes, though. Although in the generator there isn't really a designation at all, only ranges and indexes, so it probably doesn't matter what we call them here.
Yeah, that thought struck me, but renumbering could have led to confusion with the old numbering scheme. We could use Greek letters, Hebrew letters, Tengwar, or Hiragana, if you wish.
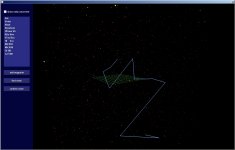
Just a screenshot showing the short-range pathfinding in action. Works really well, and since I implemented route visualisation it's really fun:
*drools*
I have a Python script that processes an Excel file full of star data, and spits out link information in one format for my star visualizer (which I grabbed off the web), and another format for my graph visualizer (also grabbed off the web). The star visualizer only lets me see all links at once or none, so I can't do the whole "highlight a route" thing.
(Exporting to the star visualizer format was also a pain in the rear. It uses a binary format that doesn't match up to its documentation, so I had to open up a valid file and compare to what I was generating, and then guess and check until I could get the program to use what I had generated.)
Columbia42
Member
I think that designating letters to the mass classes might lead to some confusion with spectral classes, though. Although in the generator there isn't really a designation at all, only ranges and indexes, so it probably doesn't matter what we call them here.
You could change the order of the numbers so that the lowest mass class would be 0 and then you could just extend the numbers upwards so that E=5, F=6, G=7 and so on.
Making slow progress on a long-range search algorithm. I expected the numbercrunching to be pretty bad... it's worse! 
Linguofreak
Well-known member
Making slow progress on a long-range search algorithm. I expected the numbercrunching to be pretty bad... it's worse!
Since there is some correlation between the links and real space, might you limit things to links going in the general direction of the target? Then again, you're probably looking at O(n^2) or (n^3) (or worse) with very large n, and this would only reduce n, rather than actually giving a better algorithm.
Might it also help to have the user give route hints? My general intuition is that a human won't be able to create optimal routes, but should at least be able to provide a somewhat good route that the computer might be able to optimize more easily than just crunching a route from scratch.
Well, the layout currently looks like this (not yet fully implemented, so I don't know yet what results it will yield):
Algorithm calculates the total distance between target and origin, and looks for a mass class in the surroundings of the target that provides a jump distance close to that distance. If it finds one (optimum case) it does the same with the origin. If it finds one that is linked to the one found before that's the best case scenario. It then calculates the jumps to and from the main link to target and origin with the short range algorithm, and that's that.
The problem is of course that the chances of finding such a link aren't very good... The algorithm will have to generate more surrounding cubes to widen the search, around Target and Origin. One of the optimisation questions that pop up is how wide the search should be. There's of course the case that the major link is too far from either origin or target, rendering the optimum distance invalid, but for really long jumps that would be quite some space to generate.
If that method is unsuccesfull, the algorithm divides the distance by two and sees if it can find a link for that. The chances of finding one are higher because the mass decreased, but on the other hand there's now more space to generate: surroundings of Target and Origin (which already have been generated, so they don't have to be again) and some space halfway in between (given that a suitable star for the jump has been found near the Target and the Origin). If not found, divide initial distance by 3, and keep going... I'm not yet sure how long I should keep it running, as I haven't gotten that far yet.
This should result in a near optimum solution in at least some cases, I hope...
As for the player giving route hints, the algorithms always search from the latest waypoint, so the player can go looking for potent long-distance jumps himself, and let the computer calculate the route to those. You can have any combination of custom assigned waypoints and computer generated paths you want (as long as the stars are linked, of course).
Another problem is that the short range algorithm itself becomes really slow when there are enough stars involved. I experimentally tried a "mid-range" search, that creates a space of 7290 cubic parsec (90x90x90) around the origin. Even in not very densly populated areas, this easily results in 100'000+ stars, which gives the breath-first algorithm an easy 10 to 15 minutes to find a solution, so such brute force aproaches are completely out of the question.
And as if this wasn't enough, the whole dynamic of travel changes on long distances. Jumping 20 lightyears into the opposite direction might still very well pay off if you reach a star that allows you to jump 200 lightyears towards the target. So I always have to do surrounding checks, I can't just go into the direction of the target...
I'll just have to do good old try and error. The mid-range aproach has already proven itself completely useless, I'll see how this method fares. If it needs 5+ minutes processing time too, Maybe I'll learn enough doing it to come up with something smarter.
Algorithm calculates the total distance between target and origin, and looks for a mass class in the surroundings of the target that provides a jump distance close to that distance. If it finds one (optimum case) it does the same with the origin. If it finds one that is linked to the one found before that's the best case scenario. It then calculates the jumps to and from the main link to target and origin with the short range algorithm, and that's that.
The problem is of course that the chances of finding such a link aren't very good... The algorithm will have to generate more surrounding cubes to widen the search, around Target and Origin. One of the optimisation questions that pop up is how wide the search should be. There's of course the case that the major link is too far from either origin or target, rendering the optimum distance invalid, but for really long jumps that would be quite some space to generate.
If that method is unsuccesfull, the algorithm divides the distance by two and sees if it can find a link for that. The chances of finding one are higher because the mass decreased, but on the other hand there's now more space to generate: surroundings of Target and Origin (which already have been generated, so they don't have to be again) and some space halfway in between (given that a suitable star for the jump has been found near the Target and the Origin). If not found, divide initial distance by 3, and keep going... I'm not yet sure how long I should keep it running, as I haven't gotten that far yet.
This should result in a near optimum solution in at least some cases, I hope...
As for the player giving route hints, the algorithms always search from the latest waypoint, so the player can go looking for potent long-distance jumps himself, and let the computer calculate the route to those. You can have any combination of custom assigned waypoints and computer generated paths you want (as long as the stars are linked, of course).
Another problem is that the short range algorithm itself becomes really slow when there are enough stars involved. I experimentally tried a "mid-range" search, that creates a space of 7290 cubic parsec (90x90x90) around the origin. Even in not very densly populated areas, this easily results in 100'000+ stars, which gives the breath-first algorithm an easy 10 to 15 minutes to find a solution, so such brute force aproaches are completely out of the question.
And as if this wasn't enough, the whole dynamic of travel changes on long distances. Jumping 20 lightyears into the opposite direction might still very well pay off if you reach a star that allows you to jump 200 lightyears towards the target. So I always have to do surrounding checks, I can't just go into the direction of the target...
I'll just have to do good old try and error. The mid-range aproach has already proven itself completely useless, I'll see how this method fares. If it needs 5+ minutes processing time too, Maybe I'll learn enough doing it to come up with something smarter.
This might be a silly idea but here goes nothing.
How about using something like the mass relays from Mass effect? Dividing the galaxy into sectors with a mass relay in each would reduce the distance required to be calculated. :hmm:
How about using something like the mass relays from Mass effect? Dividing the galaxy into sectors with a mass relay in each would reduce the distance required to be calculated. :hmm:
Well, it would be more or les similiar to what we have. I like this system because it keeps a certain level of complexity, not making things too easy. Of course the complexity also means that stuff is more... well, complex to code.
I could, in theory, cheat in the stellar generation and have some well placed high-mass stars around so I'd know in advance where they are, but that's a sacrifice I'm not willing to make. The FTL-system is there to get around faster, I won't let it dictate the fabric of the universe... The whole trouble in a random generator really is that you can't predict anything. Which is of course its purpose.
I could, in theory, cheat in the stellar generation and have some well placed high-mass stars around so I'd know in advance where they are, but that's a sacrifice I'm not willing to make. The FTL-system is there to get around faster, I won't let it dictate the fabric of the universe... The whole trouble in a random generator really is that you can't predict anything. Which is of course its purpose.
Linguofreak
Well-known member
And as if this wasn't enough, the whole dynamic of travel changes on long distances. Jumping 20 lightyears into the opposite direction might still very well pay off if you reach a star that allows you to jump 200 lightyears towards the target. So I always have to do surrounding checks, I can't just go into the direction of the target...
I guess I can rephrase it by saying "How much time can you save by sacrificing optimality, and how much optimality do you have to sacrifice to save a significant amount of time".
Other thoughts: Might it help to keep a catalog of high-mass stars cached somewhere?
What's the absolute quickest you can generate a solution, no matter how suboptimal? If you can do it in a few seconds or less over fairly large distances, you could start with a bad solution and work towards a good solution and display information on the current solution to the user (Number of jumps, confidence of optimality, estimated time to generate a solution with one less jump (or two less jumps, or three, four, ... , n)). The user can then end optimization once they are tired of waiting and/or the solution is good enough.
Might it help to use properties of the tables to conduct your search? I have things set up so that high-mass to low-mass jumps (and vice versa) have the shortest range, low-mass to low-mass have short ranges, but better than high-to-low, and high-to-high have the longest ranges.
Linguofreak
Well-known member
I could, in theory, cheat in the stellar generation
Speaking of cheating in stellar generation, is there any way you could get it to generate high mass stars first? I suppose not, since you are simulating stellar evolution and high-mass stars are younger, but it would be convenient to be able to get information on high mass stars without the computational cost of generating low mass stars in the same area (which is why I suggested caching high mass stars).
Another possible feature, which would need similar provisions for high mass stars, would be overwriting star.bin for every new system entered, so that the sky in each system actually reflects its position in the galaxy, rather than being a rehash of Earth's sky.
Speaking of cheating in stellar generation, is there any way you could get it to generate high mass stars first?
I was thinking the exact same thing a few minutes ago. It would need a bit of restructuring at least, and I don't see yet how it can exactly be realised without screwing up statistics, but if the highest mass star would be generated first, that would make things a lot easier. I have to think about it some more.
Another possible feature, which would need similar provisions for high mass stars, would be overwriting star.bin for every new system entered, so that the sky in each system actually reflects its position in the galaxy, rather than being a rehash of Earth's sky.
Yap, that would indeed come in very handy.
Guess you've done the calculations already, but how much disk space would it take to put all currently catalogued objects into the OGalaxy?
There's currently 120'000 real stars in Orbiter Galaxy. The catalogue is somewhere around 10 Mb, so more could be added. But I don't intend to have large parts of the galaxy created by LOD from file. It doesn't make the job that much easier, though...
Linguofreak
Well-known member
I've tried out V 0.6.1 (I'd previously had 0.5.3), and things are looking pretty good for the standalone client. I'm not even seeming to have any trouble with DirectX. I still haven't tried the plugin, and I have a feeling it will fail horribly under OGLAClient.
By the way, I found one thing: Moons don't have a space for their length-of-month to be displayed. They display a length-of-year equal to the parent planet, labeled as such, so it's not really a bug, just a feature request.
That said, I've found a planet moon system in 345.7e0.c9122.3c (default seed and configuration) where the moon has half the mass of the planet (both are terrestrials) the orbital period is 64 hours, and the planet and moon are not locked to each other (days of 14 and 16 hours). I'm pretty sure that in reality both would be locked.
The innermost planet in 345.7j-0.1i9111.3i (I think it's a "-" that I'm seeing between the j and the 0, I'm not sure. It's an F9V in the same sector as the aforementioned planet/moon pair), is listed as having a Greenhouse Effect despite having no atmosphere. I'm afraid I'm going to have to call the Global Warming crowd's bluff on this one... :lol: (Just checked, its moon and the next planet out are also affected by this).
A slight display typo: in the "Mass" field for planets, "kilogram" is abbreviated with a capital K, ie, as "Kg" instead of "kg". All other uses of "kg" that I can find are correct.
---------- Post added at 01:46 ---------- Previous post was at 00:35 ----------
Oh. And Barnard's star is listed as G0V with 1.72 (!!!) Solar Luminosities. In reality it's M4V.
---------- Post added at 02:01 ---------- Previous post was at 01:46 ----------
And, I believe I already mentioned this (I'd certainly foreseen and mentioned the possibility for it to occur, and I believe I also caught a few examples back in 0.5.3), but the program is procedurally generating bright stars close enough to Earth that we'd notice if they actually existed. 0.a0.1g9.4e is an example. It's an F6V in the same sector as Sol. (I'm going to say it's about as far away as Procyon).
By the way, I found one thing: Moons don't have a space for their length-of-month to be displayed. They display a length-of-year equal to the parent planet, labeled as such, so it's not really a bug, just a feature request.
That said, I've found a planet moon system in 345.7e0.c9122.3c (default seed and configuration) where the moon has half the mass of the planet (both are terrestrials) the orbital period is 64 hours, and the planet and moon are not locked to each other (days of 14 and 16 hours). I'm pretty sure that in reality both would be locked.
The innermost planet in 345.7j-0.1i9111.3i (I think it's a "-" that I'm seeing between the j and the 0, I'm not sure. It's an F9V in the same sector as the aforementioned planet/moon pair), is listed as having a Greenhouse Effect despite having no atmosphere. I'm afraid I'm going to have to call the Global Warming crowd's bluff on this one... :lol: (Just checked, its moon and the next planet out are also affected by this).
A slight display typo: in the "Mass" field for planets, "kilogram" is abbreviated with a capital K, ie, as "Kg" instead of "kg". All other uses of "kg" that I can find are correct.
---------- Post added at 01:46 ---------- Previous post was at 00:35 ----------
Oh. And Barnard's star is listed as G0V with 1.72 (!!!) Solar Luminosities. In reality it's M4V.
---------- Post added at 02:01 ---------- Previous post was at 01:46 ----------
And, I believe I already mentioned this (I'd certainly foreseen and mentioned the possibility for it to occur, and I believe I also caught a few examples back in 0.5.3), but the program is procedurally generating bright stars close enough to Earth that we'd notice if they actually existed. 0.a0.1g9.4e is an example. It's an F6V in the same sector as Sol. (I'm going to say it's about as far away as Procyon).
By the way, I found one thing: Moons don't have a space for their length-of-month to be displayed. They display a length-of-year equal to the parent planet, labeled as such, so it's not really a bug, just a feature request.
oh... I never noticed that, but when I go through the code in my head it's pretty obvious. Should theoretically not be so for moons around gas giants (i.e. I think there the year indeed is the month), but I'll have to fix that.
Tidal locking between planets and moons isn't implemented at all yet, except for moons around gas giants, since thy are generated with a completely different aproach than moons around common planets. Moons around common planets are currently formed by (probable) collision, while the moons around gas giants are accreted. Tidal effects of all kinds will be a major concern in the developement of 0.7, so you can expect that to get fixed.
There are several errors in the catalogue (for example Sirius has the classification of Sirius B (white dwarf) while having mass and luminosity of Sirius A. I'll probably never spot them all, but those known will get fixed for 0.7, as will the generation of too luminous stars in the solar vicinity. There's only a very arbitrary check currently, and I'll introduce one based on aparent magniutde at sol (just what would be a sensible cut-off for aparent magnitude? you probably got a suggestion for that).
No Idea where the magical greenhouse effect comes from, but should be easily fixable. I wonder if it actually affects the temperature or if just the flag is set for some weird reason. Thanks for reporting!
In general, the generation routines of 0.6.1 are still pretty much the same as they were in the demo. However, the report is welcome, since it's a major goal of 0.7 to do away with those things and make the whole more believable.
I came up with a concept for star generation that will allow me to generate stars in order of mass and still stays true to the initial mass function statistically. That should make things easier for the path-finding, but I'll have to brush up on probability calculations before implementing it (if I roll a die six times, how big is the probability of me roling a six once, or twice, or n times for n rolls? I know we had that somewhen back in elementary school, but I can't remember it for the live of me. But I'm sure google can help me out with it).
Similar threads
- Replies
- 4
- Views
- 529
- Replies
- 3
- Views
- 433
- Replies
- 0
- Views
- 903
- Replies
- 12
- Views
- 5K